Understanding gRPC runtime
Suppose you have a problem: in order to use new hyped shining “gRPC” communication framework, you need to be familural with it’s runtime, but networking internals is terrifyingly complicated. Here’s the result of my digging in source code presented in text form, written in order to build complete understanding of gRPC internals and design decisions and today’s networking stack.
Foreword
Easiest way to present knowladge is map, as founding fathers taught.
Since what I want to have initially is map of networking internals, I’m not planning to re-write every text from the internet. Basically, is just a bunch of references to other people (often better) maps glue together by me with some code examples.
If your innermost desire is to be drown in theoretical detals, you probably should start with Tanenbaum’s “Computer Networks”. I’ll try to focus on practical parts with rare references to this never aging classics.
Brief overview of networking layers
Feel free to skip to the next section if you could repeat from memory OSI specification, know about linux’s /dev/net/tap or could write tcp proxy without any googling.
The most popular way to describe network protocols is Open Systems Interconnection (OSI for short) model, developed by International Organization for Standardization (abbreviated as ISO for some reason). You probably saw something simular to this picture:
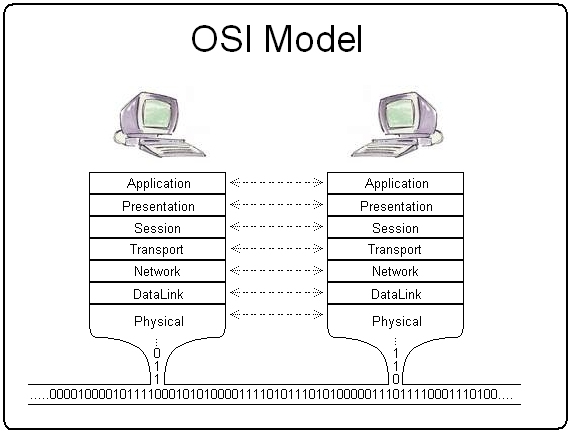
Yup, what’s basically it.
Everything you need to know about L1 (the transport layer) is what it’s based on Fourier series (explanation) and even a perfect channel has a finite transmission capacity (source).
Essential property of L2 (the data link layer) connection between two machines is that the bits are delivered is exacly the same order in which they are sent. (“wire-like” channel according to Tanenbaum). Such connections (channels) make errors occasionaly, has finite data rate (due to the L1 layer) and there’s always some delay between sending and receiving. The protocol used for commucation must take all these factors into consideration (and it usually does). The task of the data link layer is to convert the raw bit stream offered by physical layer into a stream of frames for use by network layer.
The basic purpose of L3 (the network layer) is get packets from the source all the way to the destination. Hence all routing (finding physical MAC adress given ip) is done here.
From software developer perspective, on linux L2/L3 levels could be accessed using /dev/net/tap file descriptor (what is file descriptor you could read on stackoverflow or wiki). And how to code yourself a TCP/IP stack is explained here.
L4 (The transport protocol) is layer where mind bending stuff happens. There’s two main transport protocols: TCP & UDP. UDP is commonly used in time-sensitive communications where occasionaly dropping packets is better then waiting, e.g. voice & video traffic, online games, DNS, NTP, and TCP is for everything else. Sidecars (for service meshes) and proxies (definitions for hipster’s terminology by redhat or nginx authors) sometimes could operate on L4 layer, (for example, Envoy’s tcp proxy class definition and implementation).
According to OSI where’s 2 more layers before “Application level”, whereas Tanenbaum skipped L5 & L6 (session and presentations layes accordingly) altogether. Their details are out of the scope of this blog, besides fact what ssl/tls (SSL is predecessor of TLS) encryption is done where.
Networking is layered set of thick abstractions made by humans, where every part could fail at some point. By “every part” I mean “EVERYTHING”, starting from single network card in particular server ending with whole datacenter outage. Takeaway message is simple: network is not reliable, and at some point you should deal with it. Thinking overwise is such a common misconception, what it’s even mentioned at wikipedia page about fallacies of distributed computing. I’m sure what the best example for unreliability is this quote from traceroute man page:
A more interesting example is:
[yak 72]% traceroute allspice.lcs.mit.edu.
traceroute to allspice.lcs.mit.edu (18.26.0.115), 64 hops max
1 helios.ee.lbl.gov (128.3.112.1) 0 ms 0 ms 0 ms
2 lilac-dmc.Berkeley.EDU (128.32.216.1) 19 ms 19 ms 19 ms
3 lilac-dmc.Berkeley.EDU (128.32.216.1) 39 ms 19 ms 19 ms
4 ccngw-ner-cc.Berkeley.EDU (128.32.136.23) 19 ms 39 ms 39 ms
5 ccn-nerif22.Berkeley.EDU (128.32.168.22) 20 ms 39 ms 39 ms
6 128.32.197.4 (128.32.197.4) 59 ms 119 ms 39 ms
7 131.119.2.5 (131.119.2.5) 59 ms 59 ms 39 ms
8 129.140.70.13 (129.140.70.13) 80 ms 79 ms 99 ms
9 129.140.71.6 (129.140.71.6) 139 ms 139 ms 159 ms
10 129.140.81.7 (129.140.81.7) 199 ms 180 ms 300 ms
11 129.140.72.17 (129.140.72.17) 300 ms 239 ms 239 ms
12 * * *
13 128.121.54.72 (128.121.54.72) 259 ms 499 ms 279 ms
14 * * *
15 * * *
16 * * *
17 * * *
18 ALLSPICE.LCS.MIT.EDU (18.26.0.115) 339 ms 279 ms 279 ms
Note that the gateways 12, 14, 15, 16 & 17 hops away either don't send ICMP "time
exceeded" messages or send them with a ttl too small to reach us. 14 - 17 are run-
ning the MIT C Gateway code that doesn't send "time exceeded"s. God only knows
what's going on with 12.
The silent gateway 12 in the above may be the result of a bug in the 4.[23] BSD net-
work code (and its derivatives): 4.x (x <= 3) sends an unreachable message using
whatever ttl remains in the original datagram. Since, for gateways, the remaining
ttl is zero, the ICMP "time exceeded" is guaranteed to not make it back to us. The
behavior of this bug is slightly more interesting when it appears on the destination
system:
If you’re happy linux user, you probably know what everything described above is accessible with simple cli commands (from top of my head: netcat, ifconfig & ip, tcpdump, ngrep, ping, dig, traceroute. Where’re literally dosens of them), and if you have some experience or perseverance, debugging is just matter of time, but basic understanding of abstractions you’re going to investigate is required anyway.
Or you may not need to deal with such issues at all, nor encoutered them, or not even know they exist, but someone (let’s say guys who develop kubernetes networking internals on which any web app you made is running) down the stack must design fault tolerant systems.
Transfering data over tcp
If you already know differences between major HTTP versions, know about QUIC or saw bunch of different server implementations on C, feel free to skip to next section.
Note what networks almost never looked like simple client/server communication over single TCP socket, but I’m going to write single word about ecryption & authorization, network topology and made a lot of simplifications in general.
So, suppose you want to create server which stores some data and allow clients to fetch it over network. Raw tcp is not a good fit: you’ll probably ended up with custom data representation format, with bunch of bugs or spent shitload of money to pay someone who could do it from scratch. First solution to this problem was called HTTP/0.9 and was introduced back in 1991. Simple and obvious, it looks like this:
$ nc google.com 80
GET /
HTTP/1.0 200 OK
# ... headers and response body...
But scariest part is yet to come: standards develop and grow. Back in 2000 network looked like this:
IPv4 -> TCP -> SSL/TLS* -> HTTP/1.1
- (TLS was developed later and at some point mostly replaced SSL, but encryption wasn’t what popular back in the good old days)
And as of 2019 it looks like this:
IPv6 -> TCP -> TLS v1.3 -> HTTP/2
Good introduction to HTTP/2 is here, or simply read RFC spec. Basically, HTTP/2 introduced new incompatable binary framing level, and some optimizations to reduce latency between communication endpoints, such as:
request multiplexing, which is, basically, using single TCP connection for different requests. Important note here: since HTTP/2 connections are persistant, choosing right strategy for load balancing is not so trivial as in HTTP/1 case, more about it (from gRPC standpoint) below.
bidirectional streams. Since each http request/response could be splitted into multiple frames, the order in which the frames delivered by client/server becomes perfomance consideration, hence streams could be assigned “priority” with value from 1 to 256 and be dependant on each over.
headers compression. Since sessions are persistent, server could simply “memorize” headers and reuse them for following requests.
Probably, most notable perfomance increase was experiences by end clients (such as browsers). If your setup is simply nginx as reverse proxy with fastcgi, uwsgi etc., you could simple use HTTP/2 only on frontend server and sleep peacefully. More on this in nginx blog.
I haven’t found any good HTTP/2 perfomance analysis for cluster deployments, probably, because it’s not so easy to do it well.
Personally I found Golang code simplest to read, if interested, you could compare http/2 server or client implementation with http/1 server and client, or use any language of your choise.
As always with new and technicly complex technologies, HTTP/2 has list of major vulnerabilities already discovered (as of August 2019), and yet to be found. Just keep in mind what every popular and evolving project has some. Here’s list of affected products.
Foreseeable future
And discussion around HTTP/3 already started to heat. Careful readers will notice what for 20 years straight TCP practically does not change at all, but it has it’s own problems, which some companies tries to address in so called HTTP/3, or QUIC. It have been developed using agile techniques, hence more then 12 versions of RFC proposal, cloudflare blog has good intro to QUIC, or rust implementation unnouncment post.
Introducing gRPC
Actually, gRPC consists of many different projects. Protobuf used by default for encoding/decoding (optional, you may use json). Basically, for every supported language, except Golang and Java, it looks as follows:

Golang gRPC stack:

Same source. Java’s practically has the same.
So, why does gRPC runtime seems so large and complicated? Original developers at google could not allow themselfes to rely on someone’s own http/2 implementation, so they write their own – what’s part one of runtime. Also protobuf is good, language agnostic, universal data encoding/decoding library optimized for memory usage, and it’s not so easy to implement – again, part of runtime.
And gRPC is so much more! It has authorization, compression (you may use gzip if want to, lz4 support may be added in future), connection timeouts (so called deadlines), eazy to use bidirectional streems (imagine implementing this on your own), request metadata, middleware (with pluggable validators) etc. It has large ecosystem in general.
reading source
Time spent reading gRPC source code could be exciting experience, here’s github repo with basic golang setup. Understanding source “as it is” without particular purpose to change something is separate ability to gain, and you’re advised to at least finish this post and make yourself familural with the docs.
routing
Because of all of HTTP/2 goodies described above, routing in gRPC is not as trivial as it was in HTTP/1 times. Basically, load balancing could be done at client side (using service mesh, also called as lookaside load balancing) or server side (using proxy), and implemented at l3/l4 transport layers or at application level. Usage scenarious has following properties:
- client trustworthiness
- resource utilization in proxy requirements
- latency
- storage or compute affinity
You may stop for a minute and thinks, which kind of deployments has which properties, and how you would setup routing in each case. Or read gRPC tutorial on topic, and simplest kubernetes solution may be useful, too
pros/cons
And I would argue what everything listed above is not gRPC main features. Main feature is single source of truth for client and server. Humands are terrible at contract compliances. You may use jsonschema or simular validators, but it what case you have multiple sources: one is your code, and other is schema definition. In gRPC case, code is generated from definition, and human errors still possible, but much less likely. Designing fault tolerant systems using proto is simpler, e.g. protolock. More about gRPC api versioning.
So, cons:
requires some change in reasoning about architecture & code. gRPC starting from 3th version uses golang like zero values and all fields are optional by default (starting from third version), but what’s definetly a good thing, explanation is here. Also, streams is not so easy to adopt, but pays well if used properly (e.g. lambda architecture “handles massive quantities of data by taking advantage of both batch and stream-processing methods”, more on lambda).
in case of c/c++ ffi bindings you may encounter problems at some point, and you need not to be scaried away by production grade c++ code in order to determine root cause of problem. It’s simpler for go/java, but requires reading source anyway. Try out channelz if needed.
any technology/framework incroduced in your stack increases entry threshold for newcomers and going for “hyped and fashionable tech” is always bad, regardless of technology itself. Thumb rule here is simple: try it, play around, understand it, know it’s weaknesses and which problem you’re trying to solve. Don’t get yourself into hype cycle.
You need to be sure what everyone you’re working with today or will work in future, would go faster with gRPC, not slower. Increasing development speed must be main purpose. “Development speed” does not mean only “speed of typing code”. Debugging, adding new features or changing old ones always takes some part of development time, and you need to be sure those are accelerated, too.
Also, don’t forget about simple truth: finding good developers is time and energy consuming process, even if you aren’t working at third world country (such as Russia, whatever). Your project may not be what interesting to work on, you may not have enough money, you may not want to automate everything or just have bad luck finding right people.
But at some point gRPC could even replace REST in web, google already working on browser clients, although many agree what they’re not yet production ready.
So, if you not yet ready to adopt large gRPC ecosystem in your particular company, you may end up with twirp, developed by guys from twitch.tv. Yet in my opinion moving to HTTP/2 looks inevitable at some point.